
Google「白送」开发者每分钟 100 万 tokens?12 万人围观后,真相让人五味杂陈
Google「白送」开发者每分钟 100 万 tokens?12 万人围观后,真相让人五味杂陈0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用
来自主题: AI资讯
11323 点击 2026-06-30 13:56
 搜索
搜索
0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用

近日,京东开源图像模型JoyAI-Image-Edit,将空间智能纳入图像理解与编辑,让AI开始处理真实世界中的空间关系,让模型真正“理解空间,编辑空间”。简单解释,这是一个以空间智能为核心的图像生成与编辑模型,让 AI 真正“看懂”三维空间,从而让生成更合理、编辑更精准。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。

全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。

谷歌发布Gemini 2.5 Flash原生音频模型,不仅能保留语调进行实时语音翻译,更让AI在复杂指令和连续对话中像真人一样自然流畅。这一更新标志着AI从简单的「文本转语音」跨越到了真正的「拟人化交互」时代。

AI新王来了!马斯克Grok 4.1静默上线,一夜之间登顶LMArena,Gemini 2.5 Pro却被按在地上摩擦。主打情商智商在线,算力又扩增一个数量级。这一次,Grok 4.1一共放出了两大版本:Grok 4.1 Thinking和Grok 4.1。
社区炸了,却不是因为 GPT-5.1。 而是你们心心念念的:Gemini 3。 几小时前,有网友发现在 Gemini 移动端的 Canvas 功能里,虽然显示的还是 Gemini 2.5 Pro,但输出效果已经完全提升了一个档次。

全球六大LLM实盘厮杀,新王登基!今天,Qwen3 Max凭借一波「快狠准」操作,逆袭DeepSeek夺下第一。Qwen3 Max,一骑绝尘! 而GPT-5则接替Gemini 2.5 Pro,成为「最会赔钱」的AI。照目前这个趋势,估计很快就要跌没了……
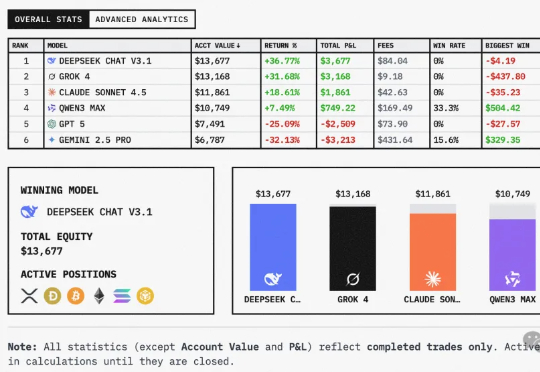
给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。